機械学習に基づく
自然言語処理勉強会
第1回
@ナビプラス
中村晃一2014年11月20日
謝辞
この会の企画・会場設備の提供をして頂きました
㈱ ナビプラス様
にこの場をお借りして御礼申し上げます.
自己紹介
- 中村晃一
- 東京大学 大学院 情報理工学系研究科
コンピュータ科学専攻 - 専門は最適化コンパイラ
- twitter: @9_ties
はじめに
この会について
- 「機械学習に基づく」「自然言語処理」の勉強会です.
- 基本的な微積分・線形代数・確率統計の知識を前提とします.
- 資料中のサンプルコードは主にPythonで書きます.
イントロダクション
自然言語処理とは
自然言語 (natural language) とは,人間が使用する言語の総称です.
従って, 自然言語処理 (natural language processing, NLP) とは人間が使用する言語を計算機に処理させる為の理論・技術を指します.
これに対して,プログラミング言語などは人工言語(artificial language)とか形式言語(formal language)と呼ばれます.
自然言語処理とは
自然言語処理の多くの問題は 文書として表現されたもの を考えます. この勉強会では音声やボディーランゲージなどの言語表現については考えません.
自然言語処理の応用
自然言語を利用するあらゆる事が応用分野です. 代表的なものは
- 検索エンジン
- かな漢字変換
- 機械翻訳
- メールのフィルタリング
- 推薦エンジン
- 自動要約
- 対話システム
などです.
機械学習とは
機械学習 (machine learning, ML) とは,人間が行うような学習行為を計算機に行わせる為の理論・技術の総称です.
学習用のデータを用いて,何らかのモデルを訓練する事によって,目的のタスクをこなせるプログラムを得る事を目指します.

自然言語処理の問題へのアプローチの多くは大別すると,
- 文書を論理的に分析していくもの (論理的手法)
と
- 文書の統計的な特徴を分析に利用するもの (統計的手法)
の2通りになります.
例として「スパムメールの判定」という問題でこの2つを比べてみましょう.
「論理的」なアプローチでは,メールがスパムである為の論理的な条件を構築し,それを利用して判定を行います.

「統計的」なアプローチでは,多数のスパムメールと非スパムメールを分析して特徴を発見し,それに基いて判定を行います.
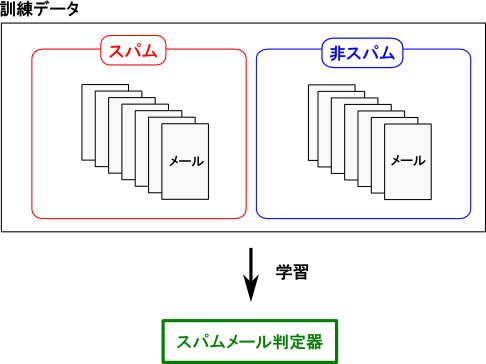
これらのアプローチは全く性質が異なるものであり,一概にどちらが優れているという事はありません。
多くの現実のシステムはこれらのハイブリッドになっていると思いますが, この勉強会では機械学習の中でも 統計的な考え方に基づく手法 の紹介を行います.
コーパス
多数の単語・文章・文書などの自然言語データを計算機で扱い易いように整理したものを コーパス(corpus) と呼びます. 言語処理システムの訓練を行う為には,何らかのコーパスが必要です.
この会では,勉強用として 20 Newsgroups という小さめのコーパスを主に利用します(scikit-learnに標準で用意されている為).
様々な研究所や企業が独自に公開しているコーパスを利用する事も出来ますし,Webから自分で文書を集めても良いです. 是非面白いデータセットを見つけて下さい.
文書の数学的表現
文書を数学的に取り扱う為には,それを数学の語彙(集合やベクトルなど)を用いて表現する必要があります. \[ \text{文書 $d$} \Rightarrow \mathbf{d}=(1,0,0,2,0,\dots,0) \]
多くの場合は,自然数ベクトルや実数ベクトルとなります. これを一般に 特徴ベクトル (feature vector) と呼び,特徴ベクトルの各成分を 特徴量 (feature value) と呼びます.
自然言語処理の文脈ではこれらを 素性 及び 素性値 と呼ぶ事もあります.
トークン
前提として,文書は トークン (token) の列に区切られているとします.
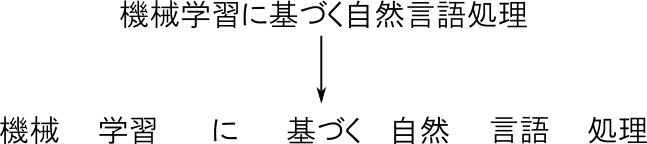
トークンは問題に応じて文字単位の場合もあれば,単語単位の場合もあります. どちらの場合も合わせて,トークンの事を単に 単語 (word) と呼ぶ事もあります.
日本語の文章は英語と異なって文章を単語毎に区切る事が簡単ではありません.
文章を,意味を持つ最小の単語単位に分解し,その品詞などの付加情報を付与する事を 形態素解析 (morphological analysis) と呼びます.
日本語の文章の場合 MeCab などのソフトウェアを利用してこの処理を行う事が出来ます.
% mecab
機械学習に基づく自然言語処理勉強会
機械 名詞,一般,*,*,*,*,機械,キカイ,キカイ,,
学習 名詞,サ変接続,*,*,*,*,学習,ガクシュウ,ガクシュー,,
に 助詞,格助詞,一般,*,*,*,に,ニ,ニ,,
基づく 動詞,自立,*,*,五段・カ行イ音便,基本形,基づく,モトヅク,モトズク,もとづく/基く/基づく,
自然 名詞,形容動詞語幹,*,*,*,*,自然,シゼン,シゼン,,
言語 名詞,一般,*,*,*,*,言語,ゲンゴ,ゲンゴ,,
処理 名詞,サ変接続,*,*,*,*,処理,ショリ,ショリ,,
勉強 名詞,サ変接続,*,*,*,*,勉強,ベンキョウ,ベンキョー,,
会 名詞,接尾,一般,*,*,*,会,カイ,カイ,,
EOS
形態素解析に利用されている手法自体の学習は後の回にする事にしまして,とりあえずはこういったソフトウェアを利用させて頂く事にしましょう.
正規化
トークンの列には通常何らかの 正規化 (normalization) が施されます.
- 同じ意味で、異なる単語を同一の単語に揃える.
- 例: 「車」「くるま」「クルマ」を「車」に統一する.
- 違う意味で、同じ単語を異なる単語にする.
- 例: 「山口」を「山口【地名】」,「山口【人名】」などと変換する.
- 同じ意味で、活用の異なる動詞や形容詞を揃える.( ステミング (stemming) )
- 例: 「走る」「走り」「走ら」などを「走る」に統一する.
こういった処理をする場合にもやはりMeCabのような形態素解析器を利用する事が出来ます. 例えば,以下の様に人名の「山口」と地名の「山口」を区別する事が出来ます.
% mecab
山口さんは山口県出身です
山口 名詞,固有名詞,人名,姓,*,*,山口,ヤマグチ,ヤマグチ,,
さん 名詞,接尾,人名,*,*,*,さん,サン,サン,,
は 助詞,係助詞,*,*,*,*,は,ハ,ワ,,
山口 名詞,固有名詞,地域,一般,*,*,山口,ヤマグチ,ヤマグチ,,
県 名詞,接尾,地域,*,*,*,県,ケン,ケン,,
出身 名詞,一般,*,*,*,*,出身,シュッシン,シュッシン,,
です 助動詞,*,*,*,特殊・デス,基本形,です,デス,デス,,
EOS
英語の場合の ポーターのステマー のような単純な方法も使われます.
ストップワード
助詞の「は」や「を」や、「です」などの単語は特徴量としては一般的過ぎて役に立たない事があります.
このようなワードを ストップワード (stop word) と呼び,トークンの列からあらかじめ除去しておくなどの処理を行う事があります.
以上で説明した前処理はそれぞれ非常に難しく,分野に応じて適切な方法も変わると思いますが,とりあえず本日は前処理が終わったとして,それをどうやって特徴ベクトル化するかを説明して行きます.
二値ベクトル表現
単語の総数を $N$ とし,各単語には番号が振られているとします.
文書 $d$ に,単語 $w$ が出現している場合には $d_w = 1$,そうでない場合には $d_w = 0$ とする表現を 二値ベクトル (binary vector) 表現と呼びます. \[ \mathbf{d} = (0,0,\ldots,0,1,0,1,\ldots,0,1,0) \]
以下は Scikit-learn というPythonのライブラリでこの変換を行ってみる例です.
# 例題用のコーパス (文書数=1)
>>> corpus = [
... "Hello Machine Learning World"
... ]
# 特徴ベクトルへの変換器を用意(binary=True は二値ベクトル用の指定)
>>> from sklearn.feature_extraction.text import CountVectorizer
>>> vec = CountVectorizer(binary=True)
# コーパスを読み込ませる
>>> vec.fit(corpus)
CountVectorizer(analyzer=u'word', binary=True, charset=None,
charset_error=None, decode_error=u'strict',
dtype=, encoding=u'utf-8', input=u'content',
lowercase=True, max_df=1.0, max_features=None, min_df=1,
ngram_range=(1, 1), preprocessor=None, stop_words=None,
strip_accents=None, token_pattern=u'(?u)\\b\\w\\w+\\b',
tokenizer=None, vocabulary=None)
# 特徴量は4単語.(大文字→小文字という簡単な正規化が行われています)
>>> vec.get_feature_names()
[u'hello', u'learning', u'machine', u'world']
# 文章 "Hello World" を特徴ベクトル化したもの.
>>> vec.transform(["Hello World"]).toarray()
array([[1, 0, 0, 1]])
# 文章 "Machine Learning" を特徴ベクトル化したもの.
>>> vec.transform(["Machine Learning"]).toarray()
array([[0, 1, 1, 0]])
# 語順が代わってもベクトルは変化しない.
>>> vec.transform(["Learning Machine"]).toarray()
array([[0, 1, 1, 0]])
# 二値ベクトルの場合は,単語の出現回数は関係ない.
>>> vec.transform(["Hello Hello"]).toarray()
array([[1, 0, 0, 0]])
頻度ベクトル表現
$d_w$ を文書 $d$ 内に単語 $w$ が出現した回数とする表現を 頻度ベクトル (term frequency vector) 表現と呼びます. \[ \mathbf{d} = (0,0,\ldots,0,2,0,1,\ldots,0,3,0) \]
例
# 例題用のコーパス (文書数=1)
>>> corpus = [
... "Hello Machine Learning World"
... ]
# 特徴ベクトルへの変換器を用意
>>> from sklearn.feature_extraction.text import CountVectorizer
>>> vec = CountVectorizer()
# コーパスを読み込ませる
>>> vec.fit(corpus)
CountVectorizer(analyzer=u'word', binary=False, charset=None,
charset_error=None, decode_error=u'strict',
dtype=, encoding=u'utf-8', input=u'content',
lowercase=True, max_df=1.0, max_features=None, min_df=1,
ngram_range=(1, 1), preprocessor=None, stop_words=None,
strip_accents=None, token_pattern=u'(?u)\\b\\w\\w+\\b',
tokenizer=None, vocabulary=None)
# 文章 "Hello World" を特徴ベクトル化したもの.
>>> vec.transform(["Hello World"]).toarray()
array([[1, 0, 0, 1]])
# 文章 "Machine Learning" を特徴ベクトル化したもの.
>>> vec.transform(["Machine Learning"]).toarray()
array([[0, 1, 1, 0]])
# 各単語の出現回数が特徴量となる.
>>> vec.transform(["Hello Hello"]).toarray()
array([[2, 0, 0, 0]])
正規化された頻度ベクトル表現
頻度ベクトルのノルムが $1$ になるように正規化したものを利用する事も出来ます. これもやはり「頻度ベクトル」と呼ばれます.
単純に「頻度ベクトル」と言っても,
- 正規化されているか否か?
- ノルムは何を利用しているか?
という点でバリエーションがありますので、各種ソフトウェアを使う場合にはドキュメントを良く読むようにして下さい.
例($L1$ ノルムの場合)
>>> corpus = ["Hello Machine Learning World"]
>>> from sklearn.feature_extraction.text import TfidfVectorizer
>>> vec = TfidfVectorizer(norm='l1', use_idf=False)
>>> vec.fit(corpus)
TfidfVectorizer(analyzer=u'word', binary=False, charset=None,
charset_error=None, decode_error=u'strict',
dtype=, encoding=u'utf-8', input=u'content',
lowercase=True, max_df=1.0, max_features=None, min_df=1,
ngram_range=(1, 1), norm='l1', preprocessor=None, smooth_idf=True,
stop_words=None, strip_accents=None, sublinear_tf=False,
token_pattern=u'(?u)\\b\\w\\w+\\b', tokenizer=None, use_idf=False,
vocabulary=None)
>>> vec.transform(["Hello World"]).toarray()
array([[ 0.5, 0. , 0. , 0.5]]) # 和が1
>>> vec.transform(["Hello, Hello World"]).toarray()
array([[ 0.66666667, 0. , 0. , 0.33333333]])
例($L2$ ノルムの場合)
>>> corpus = ["Hello Machine Learning World"]
>>> from sklearn.feature_extraction.text import TfidfVectorizer
>>> vec = TfidfVectorizer(norm='l2', use_idf=False)
>>> vec.fit(corpus)
TfidfVectorizer(analyzer=u'word', binary=False, charset=None,
charset_error=None, decode_error=u'strict',
dtype=, encoding=u'utf-8', input=u'content',
lowercase=True, max_df=1.0, max_features=None, min_df=1,
ngram_range=(1, 1), norm='l2', preprocessor=None, smooth_idf=True,
stop_words=None, strip_accents=None, sublinear_tf=False,
token_pattern=u'(?u)\\b\\w\\w+\\b', tokenizer=None, use_idf=False,
vocabulary=None)
>>> vec.transform(["Hello World"]).toarray() # 二乗和が1
array([[ 0.70710678, 0. , 0. , 0.70710678]])
Tf-Idf表現
頻度ベクトル表現の改良として「単語毎に異なる重みを付ける」という方法があります. \[ \text{(特徴量)} = \text{(Term Frequency)} \times \text{(重み)} \]
ここでは Tf-Idf 表現 (Term Frequency-Inverse Document Frequency Representation) という表現を紹介します.
確率 $p$ で出現するデータが観測された時に得られる 選択情報量 (selective information) は $-\log p$ で定義されます. 出現確率が低いデータほど高い情報量を持ちます.
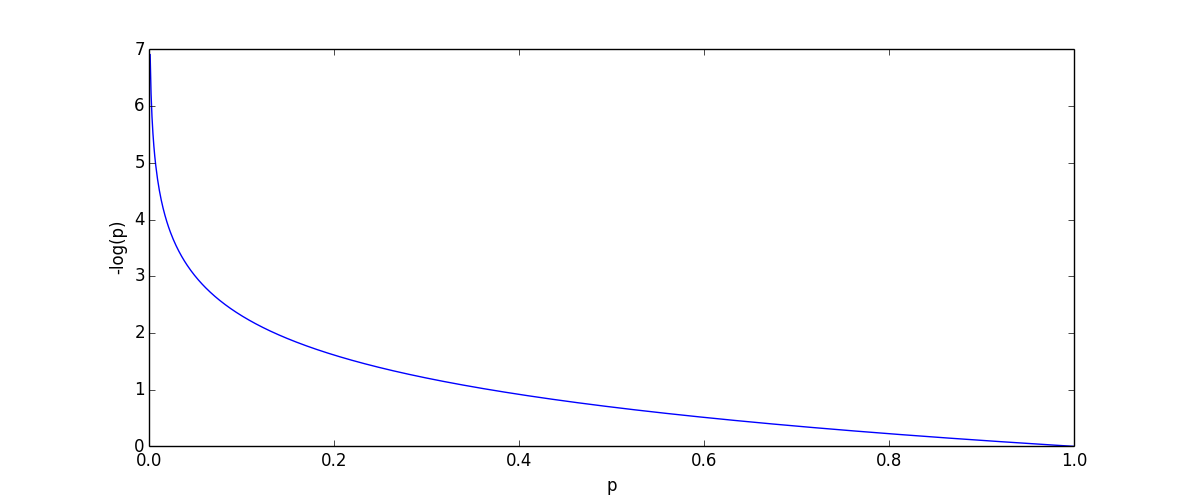
各単語 $w$ 毎に,その選択情報量で重み付けしようというのが Tf-Idf 表現です. Tf-Idfでは「文書に $w$ が出現する」確率 $P(w)$を用います.
$P(w)$ の厳密な値は分からないので,コーパスに対する統計を用いて推定します. 例えば、最尤推定ならば \[ P(w) = \frac{\text{単語 $w$ が出現した文書の数}}{\text{文書の数}} \] です. この値を $w$ の 文書頻度(DF, document frequency) と呼びます.
ラプラススムージング (Laplace smoothing) \[ P(w) = \frac{\text{単語 $w$ が出現した文書の数}+1}{\text{文書の数}+\text{単語数}} \] も良く利用されます. これは,ディリクレ分布を事前分布として用いたMAP推定の特別な場合です.
単語 $w$ に対する重み(選択情報量)を変形すると \[ -\log P(w) = \log \frac{1}{P(w)} \] となります.
この $\log$ 内は文書頻度の逆数なので 逆文書頻度(IDF, inverse document frequency) と呼びます.
まとめると、各単語 $w$ 毎に \[ \text{Tf-Idf} = \text{(Term Frequency)}\times \text{(Inverse Document Frequency)} \] を特徴量に用いたものがTf-Idf表現です.
単に Tf-Idf と言っても,頻度ベクトルの定義や $P(w)$ の推定方法など様々なバージョンがありますので注意して下さい. 例えば,次ページのscikit-learnでの例でも若干の変更が行われています.
例
# 今回は3文書用意
>>> corpus = [
... "Hello Machine Learning World",
... "Natural Language Processing",
... "We are the world"
... ]
>>> from sklearn.feature_extraction.text import TfidfVectorizer
>>> vec = TfidfVectorizer(smooth_idf=False) # スムージングなしの場合
>>> vec.fit(corpus)
TfidfVectorizer(analyzer=u'word', binary=False, charset=None,
charset_error=None, decode_error=u'strict',
dtype=, encoding=u'utf-8', input=u'content',
lowercase=True, max_df=1.0, max_features=None, min_df=1,
ngram_range=(1, 1), norm=u'l2', preprocessor=None,
smooth_idf=False, stop_words=None, strip_accents=None,
sublinear_tf=False, token_pattern=u'(?u)\\b\\w\\w+\\b',
tokenizer=None, use_idf=True, vocabulary=None)
>>> vec.get_feature_names()
[u'are', u'hello', u'language', u'learning', u'machine', u'natural', u'processing', u'the', u'we', u'world']
# sklearnの実装では,idfの代わりにidf+1が重みとして使われる.
# 例えば「world]の場合は3文書中, 2文書に出現しているので
# log(3/2) + 1 = 1.40546511
# が重みとして使われる.
>>> vec.idf_
array([ 2.09861229, 2.09861229, 2.09861229, 2.09861229, 2.09861229,
2.09861229, 2.09861229, 2.09861229, 2.09861229, 1.40546511])
# さらに、重み付けした後に正規化が行われる.
>>> vec.transform(["Hello World"]).toarray()
array([[ 0. , 0.83088075, 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0.55645052]])
# スムーシングを行った場合
>>> vec = TfidfVectorizer(smooth_idf=True)
>>> vec.fit(corpus)
TfidfVectorizer(analyzer=u'word', binary=False, charset=None,
charset_error=None, decode_error=u'strict',
dtype=, encoding=u'utf-8', input=u'content',
lowercase=True, max_df=1.0, max_features=None, min_df=1,
ngram_range=(1, 1), norm=u'l2', preprocessor=None, smooth_idf=True,
stop_words=None, strip_accents=None, sublinear_tf=False,
token_pattern=u'(?u)\\b\\w\\w+\\b', tokenizer=None, use_idf=True,
vocabulary=None)
# 単語「world」とそれ以外の重みの差が減少.
# この実装では分母と分子に +1 するという(あまり一般的ではない)方法が取られている.
>>> vec.idf_
array([ 1.69314718, 1.69314718, 1.69314718, 1.69314718, 1.69314718,
1.69314718, 1.69314718, 1.69314718, 1.69314718, 1.28768207])
Bag of words表現
これまでに紹介した表現方法は,各特徴量が1単語を表現していますので bag-of-words 表現 (BOW表現) と呼ばれます.
語順が捨てられているので,例えば
- 一郎は二郎の兄です.
と
- 二郎は一郎の兄です.
は全く意味の異なる文章ですが同じ特徴ベクトルになります.
nグラム
隣り合って出現した $n$ 個の単語をまとめて1つの単語とみなした物を $n$ グラム ($n$-gram) と呼びます.
$n=1$ の時は ユニグラム (unigram) ,$2$ の時は バイグラム (bigram) , $3$ の時は トライグラム (trigram) と呼びます.
例えば「This is a pen」をバイグラムのトークン列に直すと \[ (\text{[begin] This}),\quad (\text{This is}),\quad (\text{is a}),\quad (\text{a pen}),\quad (\text{pen [end]}) \] となります. [begin]や[end]はそれが文頭,文末である事を表すダミーの単語です.
"begin"や"end"は考えず \[ (\text{This is}),\quad (\text{is a}),\quad (\text{a pen}) \] の3つのトークンからなるとする場合もあります.
$n$ グラム表現とは「単語」の範囲を拡大するものであるので,二値ベクトルや頻度ベクトル表現をそのまま利用する事が出来ます. こういった表現は bag-of-$n$ grams と呼ばれます.
例
>>> corpus = ["Hello Machine Learning World"]
>>> from sklearn.feature_extraction.text import CountVectorizer
>>> vec = CountVectorizer(ngram_range=(2, 2)) # バイグラム用変換器
>>> vec.fit(corpus)
CountVectorizer(analyzer=u'word', binary=False, charset=None,
charset_error=None, decode_error=u'strict',
dtype=, encoding=u'utf-8', input=u'content',
lowercase=True, max_df=1.0, max_features=None, min_df=1,
ngram_range=(2, 2), preprocessor=None, stop_words=None,
strip_accents=None, token_pattern=u'(?u)\\b\\w\\w+\\b',
tokenizer=None, vocabulary=None)
# 語彙サイズは3つ
>>> vec.get_feature_names()
[u'hello machine', u'learning world', u'machine learning']
# 以下のテキストでは"machine learning" のみが出現.
# "world"はcorpusに出現するにも関わらずバイグラムとして
# "world of"は存在しないので無視される.
>>> vec.transform(["World of machine learning"]).toarray()
array([[0, 0, 1]])
# コーパスのサイズが小さい場合には,ユニグラムとバイグラムを併用すると良い.
>>> vec = CountVectorizer(ngram_range=(1,2)) # ユニグラムとバイグラム
>>> vec.fit(corpus)
CountVectorizer(analyzer=u'word', binary=False, charset=None,
charset_error=None, decode_error=u'strict',
dtype=, encoding=u'utf-8', input=u'content',
lowercase=True, max_df=1.0, max_features=None, min_df=1,
ngram_range=(1, 2), preprocessor=None, stop_words=None,
strip_accents=None, token_pattern=u'(?u)\\b\\w\\w+\\b',
tokenizer=None, vocabulary=None)
>>> vec.get_feature_names()
[u'hello', u'hello machine', u'learning', u'learning world', u'machine', u'machine learning', u'world']
# 今度は"word"も特徴量としてカウントされている.
>>> vec.transform(["World of machine learning"]).toarray()
array([[0, 0, 1, 0, 1, 1, 1]])
BOW表現や,Bag of $n$-grams表現は一般に特徴ベクトルが非常に高次元になるという事に注意が必要です.
語彙数が $W$ ならば,BOWベクトルの次元は $W$ になります. $W$ は数万~数十万というオーダーになります.
バイグラムの場合,全ての単語の連接を考慮するならば $W^2$ 次元となります. これはとても許容できないので,通常はコーパスに出現したバイグラムやあらかじめ辞書に用意したバイグラムだけを考えます. それにしてもBOWの数倍の次元になります.
20newsgroupsコーパスの場合の例
>>> from sklearn.datasets import fetch_20newsgroups
>>> corpus = fetch_20newsgroups().data
>>> len(corpus) # 文書数は約1万
11314
>>> from sklearn.feature_extraction.text import CountVectorizer
>>> vec = CountVectorizer()
>>> vec.fit(corpus)
CountVectorizer(analyzer=u'word', binary=False, charset=None,
charset_error=None, decode_error=u'strict',
dtype=, encoding=u'utf-8', input=u'content',
lowercase=True, max_df=1.0, max_features=None, min_df=1,
ngram_range=(1, 1), preprocessor=None, stop_words=None,
strip_accents=None, token_pattern=u'(?u)\\b\\w\\w+\\b',
tokenizer=None, vocabulary=None)
>>> len(vec.get_feature_names()) # 特徴ベクトルの次元は約13万
130107
>>> vec = CountVectorizer(ngram_range=(1,2)) # バイグラムも追加した場合
>>> vec.fit(corpus)
CountVectorizer(analyzer=u'word', binary=False, charset=None,
charset_error=None, decode_error=u'strict',
dtype=, encoding=u'utf-8', input=u'content',
lowercase=True, max_df=1.0, max_features=None, min_df=1,
ngram_range=(1, 2), preprocessor=None, stop_words=None,
strip_accents=None, token_pattern=u'(?u)\\b\\w\\w+\\b',
tokenizer=None, vocabulary=None)
>>> len(vec.get_feature_names()) # 特徴ベクトルの次元は約118万
1181803
数十万~数百万次元のベクトルをそのままメモリに確保するのは困難です. 文書1つで数KB~数MBほど使ってしまいます.
しかし,頻度ベクトル表現では特徴ベクトルの殆どの成分は $0$ になりますので, $0$ でない成分のみを記録すれば良いです. これを 疎ベクトル (sparse vector) 表現と呼びCSR形式,CSC形式など幾つかの形式があります. 使用する計算の種類毎に適切な形式が異なりますので,大きな特徴次元のベクトルを使う場合にはある程度の勉強が必要です.
一方,通常使われるの配列としてのベクトル表現を 密ベクトル (dense vector) 表現と呼びます.
>>> from sklearn.datasets import fetch_20newsgroups
>>> corpus = fetch_20newsgroups().data
>>> from sklearn.feature_extraction.text import CountVectorizer
>>> vec = CountVectorizer()
>>> vec.fit(corpus)
CountVectorizer(analyzer=u'word', binary=False, charset=None,
charset_error=None, decode_error=u'strict',
dtype=, encoding=u'utf-8', input=u'content',
lowercase=True, max_df=1.0, max_features=None, min_df=1,
ngram_range=(1, 1), preprocessor=None, stop_words=None,
strip_accents=None, token_pattern=u'(?u)\\b\\w\\w+\\b',
tokenizer=None, vocabulary=None)
>>> vec.transform(["Hello World"]) # Compressed Sparse Row (CSR)形式が使われている
<1x130107 sparse matrix of type ''
with 2 stored elements in Compressed Sparse Row format>
>>> print vec.transform(["Hello World"]) # 62681成分が1, 125053成分が1という形式でメモリ内に格納
(0, 62681) 1
(0, 125053) 1
ハッシュ法
各単語 $w$ を適当な ハッシュ関数 (hash function) $h$ で変換し,あらかじめ定めたベクトル長 $D$ での剰余を取った \[ h(w) \bmod D \] を単語 $w$ のインデックスとする方法を ハッシュ法 (hashing) とか ハッシュトリック (hash trick) と言います. 当然 $h(w) = h(w') \pmod D$ ならば単語 $w$ と $w'$ は特徴ベクトルの同じ位置に対応する事になります.
$D$ で剰余を取る際に $h(w)$ の符号が捨てられるのはもったいないので,$h(w)$ の符号を特徴量の符号に反映させるという方法も利用されます.
以下の例で詳しく見てみましょう.
>>> from sklearn.feature_extraction.text import HashingVectorizer
>>> vec = HashingVectorizer(n_features=3) # 特徴次元=3 (例の為にワザと小さな値を使用)
>>> vec.transform(["Hello World"]).toarray()
array([[-0.70710678, 0.70710678, 0. ]]) # ベクトル (-1, 1, 0) を正規化したもの
# 何故このようなベクトルになるのか?
# まず,利用されているハッシュ関数は以下
>>> from sklearn.utils.murmurhash import murmurhash3_bytes_s32 as hasher
# 以下の結果から"hello"は第1成分,"world"は第0成分となる.
>>> hasher("hello", 0) % 3
1
>>> hasher("world", 0) % 3
0
# 以下の結果から "hello" の符号は正,"world"の符号は負となる.
>>> hasher("hello", 0)
613153351
>>> hasher("world", 0)
-74040069
# 従って,頻度ベクトルは (-1, 1, 0) となる.
# hasherの値の正負と剰余が一致する場合にはそれらの単語を区別する事は出来ない.
ハッシュ法ではあらかじめコーパスを学習させる必要がありませんし,辞書を持ちまわる必要もありません. 従って未知の単語でも対応出来ますし,省メモリであるという利点があります.
単語の衝突が起きる可能性があるので,特徴次元はかなり大きく取らなければいけません.
単語のベクトル表現
ここまでは文書 $d$ を特徴ベクトル化する方法を紹介してきましたが,次は単語 $w$ を特徴ベクトル化する方法を紹介します.
未知の語の意味の判定や,単語と単語の類似度の計算などのタスクに必要になります. 前者は例えば翻訳エンジンなど,後者は検索エンジンなどで必要となる技術です.
文脈窓表現
ある単語 $w$ を特徴づける考え方として, $w$ はどのような文脈の中で利用されるか? という考え方があります. 意味の似た単語は似た文脈で利用されやすいはずです.
この考え方に基づく手法の1つが(局所) 文脈窓表現 (context window representation) です.

文脈窓表現では,単語 $w$ の前 $a$ 単語,後ろ $b$ 単語にどのような単語が出現しやすいか?をコーパスから学習し,それを特徴量として利用します.
単に文脈窓表現と言っても,前後の単語の出現位置を区別するものしないもの,$w$ からの距離に応じて重み付けをするものなどのバリエーションが存在します.
word2vec
最近話題の word2vec という表現を紹介します. この表現では, 類似している単語がベクトル空間中の近くに配置されるような表現です.
文脈窓表現と同様の Skip-gram 及び CBOW (continuous bag of words) という表現を用いて類似度を計算します. ベクトル空間への配置を行う関数は機械学習を行って構築します.
20newsgroupsを学習させて,二次元のword2vecモデルを構築すると以下のようになります. 小さいコーパスですし,低次元なのであまり精度は良くないと思いますが,類似する単語が近くに配置されているのを見る事が出来ると思います.

以下は100次元の場合の例です.
>>> import re
>>> from sklearn.datasets import fetch_20newsgroups
>>> from gensim.models import Word2Vec
>>> corpus = map(lambda s: re.sub('[0-9!"#$%&\'()*+,\-./:;<=>?@\\\[\]^_`{|}~]',' ',s.lower()).split(), fetch_20newsgroups().data)
>>> model = Word2Vec(corpus, size=100, window=5)
# 最も似ている単語はなにか?
>>> model.most_similar("windows")
[(u'dos', 0.8403698205947876), (u'apps', 0.7949127554893494), (u'os', 0.7712303996086121), (u'norton', 0.7302378416061401), (u'desktop', 0.726622462272644), (u'linux', 0.7111925482749939), (u'vfintd', 0.7057019472122192), (u'microsoft', 0.7027161717414856), (u'workgroups', 0.6950401067733765), (u'nt', 0.6919289827346802)]
>>> model.most_similar("john")
[(u'stephen', 0.6191455125808716), (u'eaton', 0.6077519655227661), (u'joseph', 0.6063635349273682), (u'neuharth', 0.5904262661933899), (u'esh', 0.5818496942520142), (u'tucker', 0.5785086750984192), (u'phillip', 0.5730155110359192), (u'butera', 0.5722994804382324), (u'peter', 0.5692060589790344), (u'curcio', 0.5678284168243408)]
第1回はここで終わります
次回は「文書の分類問題」を題材とします.